WHATSAPP / TELEGRAM / TELEFON: +49 176 57 95 85 04 I GHOSTWRITING. MIT WERTEN. I E-MAIL: INFO@DER-ABSCHLUSSHELFER.DE

Statistik-Know-how Teil 2
Der gelbe Engel ist back!
"Ich kann mich noch sehr gut daran erinnern, dass ich damals für das Modul Statistik lernen musste mit R zu arbeiten. Das war damals einer der härtesten Module des Studiengangs und ich habe über Wochen hinweg täglich 4-5 Stunden dafür gelernt. Ich glaube, ich war nie stolzer auf eine 1,3 als bei diesem Modul."
Amin Rafiki


280+
1,3 -Schnitt
Bei Statistikarbeiten
Statistikprojekte begleitet
12. Zusammenhänge vorhersagen: Warum Regressionen plötzlich überall auftauchen
Hinter Regressionen steht meist eine ziemlich nachvollziehbare Frage: Welche Faktoren beeinflussen etwas und wie stark tun sie das?
Viele empirische Arbeiten landen früher oder später genau hier. Die Forschungsfrage lautet dann nicht mehr: „Gibt es einen Zusammenhang?“ oder „Unterscheiden sich Gruppen?“, sondern eher: „Welche Einflussgrößen wirken auf ein Ergebnis?“ Ein Beispiel wäre: „Beeinflussen Schlafdauer, Stressniveau und Lernzeit die Prüfungsnote von Studierenden?“ Spätestens an diesem Punkt reicht eine einfache Korrelation nicht mehr aus, weil nicht nur zwei Variablen betrachtet werden sollen, sondern mehrere gleichzeitig. Genau hier tauchen Regressionen auf! Aber das wisst Ihr mittlerweile natürlich schon, denn ich habe das nicht grundlos so repetitiv in Teil 1 der Statistik-Reihe aufgeführt.
Nehmen wir an, eine Untersuchung erhebt Daten von 250 Studierenden. Erfasst werden unter anderem die durchschnittliche Schlafdauer pro Nacht, die Lernzeit pro Woche, das subjektive Stressempfinden und die letzte Prüfungsnote. Eine Regression könnte später zeigen, dass mehr Lernzeit tendenziell mit besseren Noten verbunden ist, höheres Stressniveau eher mit schlechteren Noten zusammenhängt und Schlaf einen kleineren positiven Einfluss besitzt. Das klingt zunächst tatsächlich angenehm eindeutig. Viele von Euch formulieren an dieser Stelle vorschnell Dinge wie: „Stress verschlechtert Leistungen“ oder „Mehr Schlaf verbessert Noten.“ Genau hier beginnt jedoch der Bereich, in dem Ergebnisse schnell größer wirken als die Daten selbst. Denn auch eine Regression erklärt nicht plötzlich das gesamte Verhalten von Menschen. Vielleicht besitzen Personen mit besserem Zeitmanagement weniger Stress und lernen strukturierter? Vielleicht spielt Motivation hinein? Vielleicht finanzielle Belastung, vielleicht existieren Einflussgrößen, die gar nicht erhoben wurden? Who knows! Regressionen reduzieren lediglich Unsicherheit.
Weißt Du, was ich am statistischen Arbeiten so liebe? Es ist so ehrlich und ruhig...
Füttere Deinen Senior-Ghostwriter mit hochgeschätzter Arbeit:
13. Reliabilität und Validität
Irgendwann ist der Fragebogen erstellt, die Umfrage verschickt und endlich kommen genügend Antworten zurück. Verständlich, wenn an diesem Punkt Erleichterung aufkommt und der Gedanke entsteht: „Die Daten sind da. Jetzt beginnt die Statistik.“ Tatsächlich fehlt davor manchmal noch eine ziemlich unbequeme Frage: Misst mein Fragebogen überhaupt zuverlässig das, was ich untersuchen möchte? Viele Skalen bestehen nicht nur aus einer einzelnen Frage, sondern aus mehreren Aussagen. Etwa bei Stress, Arbeitszufriedenheit, Prüfungsangst oder Persönlichkeitseigenschaften. Wenn Ihr zum Beispiel Neurotizismus untersucht, könnten Aussagen auftauchen wie: „Ich mache mir schnell Sorgen“ oder „Ich fühle mich häufig überfordert.“ Die Überlegung dahinter ist eigentlich simpel: Wenn all diese Aussagen dasselbe Merkmal messen sollen, sollten die Antworten zumindest einigermaßen zusammenpassen.
Genau hier erscheint the good old Cronbachs Alpha: ein Wert zur Prüfung der internen Konsistenz einer Skala.
Neben Reliabilität taucht ein zweiter Begriff auf, der anfangs abstrakter wirkt: Validität. Hier geht es weniger um Zuverlässigkeit und stärker um Treffgenauigkeit. Also um die Frage: Misst das Instrument wirklich das, was untersucht werden soll? Ein Fragebogen könnte sehr konsistente Antworten liefern und trotzdem am eigentlichen Thema vorbeimessen. Angenommen, Ihr möchtet Prüfungsangst untersuchen, erhebt aber überwiegend allgemeines Stressempfinden. Die Antworten können sauber zusammenpassen und dennoch nicht exakt das erfassen, was Eure Forschungsfrage verlangt.
Mein Statistik-Versprechen
"Wer immer mich für statistiklastige Projekte konsultiert, soll sich nicht nur gut geborgen fühlen, sondern auch ein tieferes Verständnis über jene Aspekte der Statistik erwerben, die seine eigene Abschlussarbeit berühren. Ich bringe Euch also nicht nur den Fisch für die akute Hungersnot, sondern ich lehre Euch auch gleich das Angeln."
Amin Rafiki


Wirtschaft
R & SPSS
Häufigste Software
Eigener Studiengang
14. Statistikprogramme im Studium: Warum Ihr nicht zuerst SPSS lernen müsst, sondern Eure Forschungsfrage verstehen solltet
Irgendwann kommt in empirischen Arbeiten der Punkt, an dem Daten nicht mehr nur in einer Excel-Tabelle liegen, sondern ausgewertet werden sollen. Genau dann tauchen Programme auf, vor denen Ihr manchmal unnötigen Respekt habt, nämlich SPSS, R, Python, Excel, Jamovi oder MAXQDA. Und oft entsteht dieselbe Sorge: „Ich habe noch nie mit SPSS gearbeitet. Bin ich jetzt verloren?“
Nach etlichen Jahren und zahllosen Projekten würde ich sogar behaupten, dass Probleme seltener daran entstehen, dass Ihr Software nicht beherrscht, sondern eher daran, dass unklar bleibt, welche Analyse überhaupt durchgeführt werden soll. Ein Programm kann viel berechnen. Es nimmt Euch aber nicht die Entscheidung ab, warum ein t-Test sinnvoller wäre als eine Korrelation oder weshalb eine Regression besser passt als eine ANOVA.
SPSS begegnet Euch vermutlich zuerst. Vor allem in Medizin, Sozialwissenschaften, Gesundheitswissenschaften oder BWL wird damit gearbeitet. SPSS wirkt anfangs technisch, besteht im Kern aber oft aus Variablen auswählen, Menüs anklicken und Ergebnisse interpretieren. Ich habe Klient:innen erlebt, die vor SPSS fast mehr Angst hatten als vor der Abgabe selbst und kurze Zeit später gemerkt haben, dass die eigentliche Schwierigkeit nicht das Programm war, sondern das Verständnis der eigenen Methodik. Glück, dass Ihr mich gefunden habt, denn ich liebe SPSS und halte es für das beste Statistik-Programm auf dem Markt. Deswegen besitze ich auch eine Jahreslizenz dafür und biete immer auch die Output- und Syntax-Datei an, wenn ich Euch unterstütze.
R wirkt meist abschreckender. Dort wird eher mit Code gearbeitet statt mit Oberflächen. Viele schließen automatisch daraus, dass R nur etwas für Informatiker oder Statistik-Nerds sei. Ganz so ist es nicht, denn gerade in der Psychologie wird R bevorzugt. Wer sich einarbeitet, merkt relativ schnell, warum: Es gilt enorme Flexibilität, gute Visualisierungen und praktisch unbegrenzte Erweiterungsmöglichkeiten. Für viele Bachelorarbeiten außerhalb der Psychologie wird R nie notwendig sein. In datenintensiveren Projekten sieht das aber ganz anders aus.
Python begegnet Euch zunehmend im Umfeld von KI, Wirtschaftsinformatik, Data Science oder großen Datensätzen. Python ist weniger ein klassisches Statistikprogramm und eher ein Werkzeugkasten. Regressionen, Datenbereinigung, Visualisierung oder Machine Learning sind damit möglich.
Excel wird erstaunlich oft unterschätzt. Doch Mittelwerte, Häufigkeiten oder Diagramme lassen sich problemlos erstellen. Irgendwann stößt Excel aber durchaus an Grenzen, nämlich wenn Analysen komplexer werden. Trotzdem reicht es für manche Auswertungen aus.
Schließlich gibt es Programme wie Jamovi, das für viele Einsteiger angenehmer wirkt. Die Oberfläche ist übersichtlich und typische statistische Verfahren lassen sich relativ schnell durchführen. Wer sich von SPSS erschlagen fühlt, empfindet Jamovi manchmal als deutlich zugänglicher. Zudem ist Jamovi komplett kostenlos.
MAXQDA gehört streng genommen in eine andere Richtung. Wenn Ihr qualitative Interviews analysiert, Kategorien bildet oder Inhaltsanalysen durchführt, taucht MAXQDA deutlich eher auf als SPSS. Wer eine qualitative Arbeit schreibt, braucht unter Umständen überhaupt keine klassische Statistiksoftware, sondern greift eher auf MAXQDA und Konsorten zu.
Übrigens schreibe ich manchmal auch in online Live-Sessions ausgewählte Hausarbeiten, während Ihr Eure Fragen stellen könnt.
Informiere Dich:
15. Typische Fehler in statistischen Auswertungen
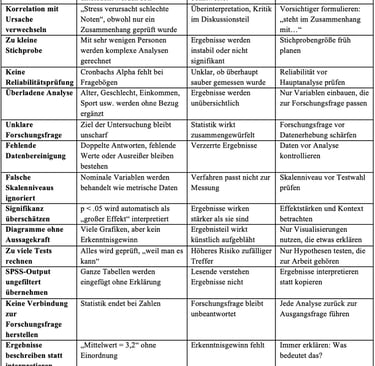
An dieser Stelle führe ich Euch einmal eine Tabelle auf, in der Ihr nachvollziehen könnt, was die häufigsten Fehler meiner Klienten sind und wie Ihr diese nachhaltig vermeiden könnt. Aus SEO-Gründen führe ich das jedoch nachfolgend auch noch einmal als Fließtext auf:
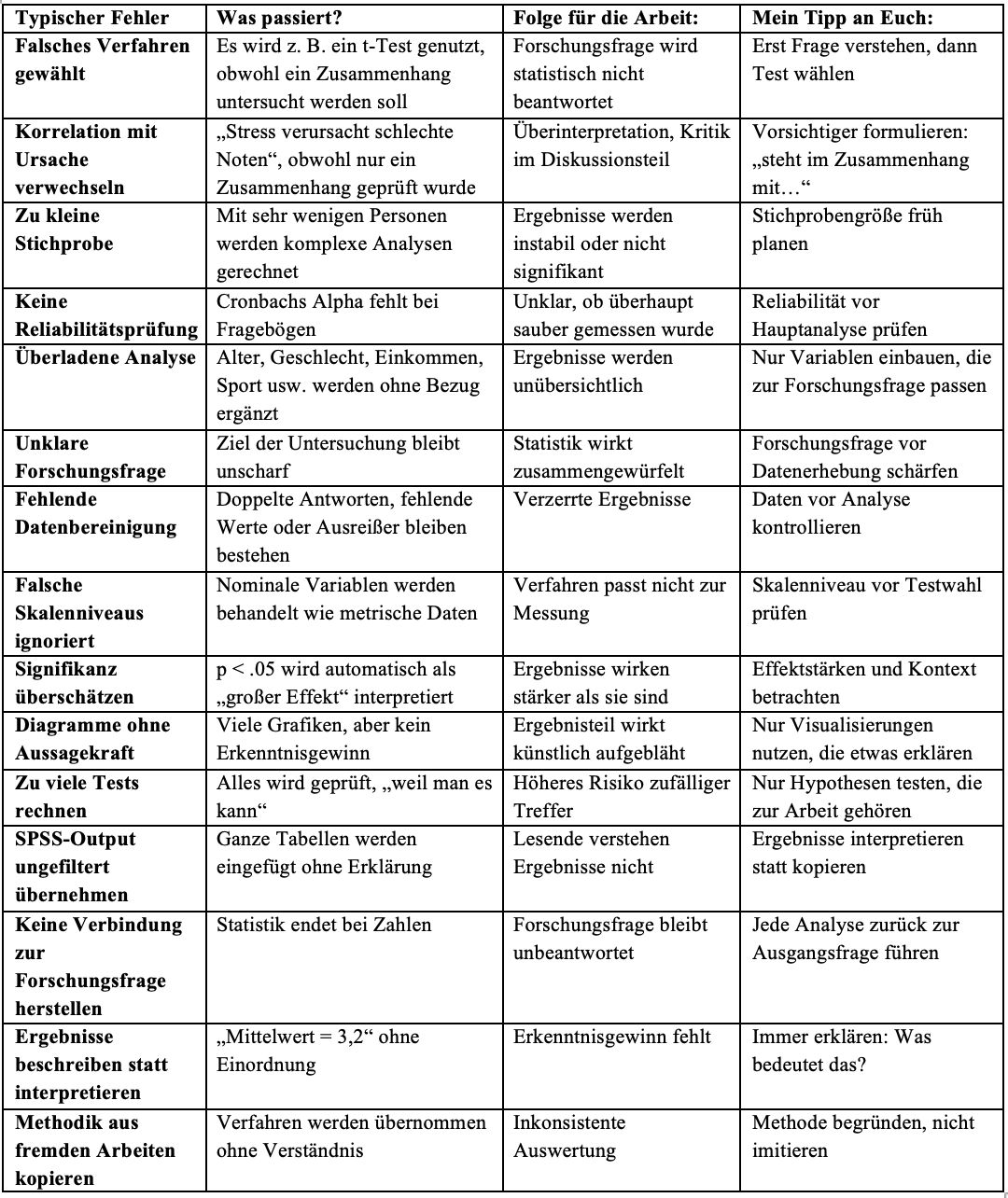
Ein häufiger Punkt ist die Wahl eines Verfahrens, das nicht zur Forschungsfrage passt. Wer einen Zusammenhang untersuchen möchte, aber Gruppenvergleiche rechnet, beantwortet am Ende statistisch nicht die eigentliche Frage. Die Lösung ist meist unspektakulär: Erst die Forschungsfrage verstehen, danach das Verfahren wählen.
Ebenfalls kritisch wird es, wenn Korrelationen vorschnell als Ursachen interpretiert werden. Aus „Stress hängt mit schlechteren Noten zusammen“ wird schnell „Stress verursacht schlechte Noten“. Solche Aussagen führen oft zu Kritik im Diskussionsteil. Vorsichtige Formulierungen sind hier meist sauberer.
Zu kleine Stichproben erzeugen häufig instabile Ergebnisse oder fehlende Signifikanz, obwohl Zusammenhänge existieren könnten. Deshalb lohnt es sich, die benötigte Stichprobengröße früh mitzudenken. Ähnlich problematisch wird es, wenn Reliabilität nicht geprüft wird. Fehlt Cronbachs Alpha bei Fragebögen, bleibt offen, ob überhaupt zuverlässig gemessen wurde.
Viele Auswertungen werden unnötig überladen. Alter, Geschlecht, Einkommen oder Sportverhalten tauchen plötzlich auf, obwohl sie zur Forschungsfrage keinen Bezug besitzen. Mehr Variablen bedeuten nicht automatisch bessere Analysen. Gleiches gilt für unklare Forschungsfragen: Wenn das Untersuchungsziel unscharf bleibt, wirkt Statistik später oft beliebig.
Auch technische Fehler kosten Qualität. Fehlende Daten, doppelte Antworten oder ungeprüfte Ausreißer können Ergebnisse verzerren. Falsch behandelte Skalenniveaus führen zusätzlich dazu, dass ungeeignete Verfahren genutzt werden. Und ein p-Wert kleiner als .05 bedeutet nicht automatisch einen starken oder praktischen Effekt. Effektstärken und Kontext bleiben entscheidend.
Relativ oft entstehen Tabellen, Diagramme oder komplette SPSS-Outputs ohne Erklärung. Zahlen allein beantworten keine Forschungsfrage. Eine gute Auswertung beschreibt Ergebnisse nicht nur, sondern ordnet sie ein. Die eigentliche Frage bleibt immer dieselbe: Was bedeuten diese Ergebnisse für die Untersuchung?
Du hast Deine Statistik selbst im Griff, brauchst aber noch eine erfahrene Meinung?
Lets get it done!
16. Statistik in Hausarbeiten, Bachelorarbeiten, Masterarbeiten und Dissertationen: Was wirklich erwartet wird
Irgendwann taucht bei vielen von uns die Frage auf: „Wie viel Statistik muss ich eigentlich können?“ Die ehrliche Antwort lautet, dass das regelmäßig weniger ist, als vermutlich angenommen wird, doch oft genug ist es doch deutlich mehr, als Euch lieb ist. Die Anforderungen unterscheiden sich nicht nur nach Studienniveau, sondern auch stark nach Fachrichtung, aber aus meiner Erfahrung als Senior-Ghostwriter gilt folgendes:
Bei Hausarbeiten steht Statistik oft im Zeichen des Lernens. Manche Dozierende nutzen empirische Hausarbeiten bewusst als Methodiktraining, bevor später Bachelor- oder Masterarbeiten folgen. Ihr begegnet hier teilweise schon Hypothesen, Mittelwerten, Korrelationen, t-Tests oder einfachen Hypothesenprüfungen. Die Datensätze bleiben meist klein und die Analysen überschaubar. Bewertet wird weniger Perfektion als das Verständnis des Prozesses. Also: Forschungsfrage formulieren, passende Methode wählen, Ergebnisse darstellen und interpretieren.
In Bachelorarbeiten steigt der Anspruch an Struktur und Nachvollziehbarkeit. Empirische Arbeiten werden viel gängiger und die Datenerhebungen deutlich umfangreicher. Fragebögen, Cronbachs Alpha, Korrelationen, Gruppenvergleiche oder Regressionen tauchen auch regelmäßig auf. Von Euch wird meist nicht erwartet, komplizierte Statistik zu beherrschen, sondern eher, dass die Methode zur Forschungsfrage passt und Ergebnisse sinnvoll eingeordnet werden. Eine einfache Analyse, die verstanden wird, wirkt hier also meist überzeugender als komplexe Verfahren ohne Begründung, Sinn und vor allem Nutzen!
Bei Masterarbeiten verschiebt sich der Schwerpunkt einmal mehr. Die Statistik muss jetzt nicht zwingend schwerer werden, aber die methodische Reflexion wird kritischer. Warum wurde genau dieses Verfahren gewählt? Welche Limitationen bestehen? Welche Alternativen wären denkbar? Die reine Berechnung reicht also seltener aus. Methodische Entscheidungen müssen zunehmend verteidigt werden können, und das setzt einmal mehr voraus, dass Ihr versteht, was Ihr da macht.
Dissertationen bewegen sich final aufgeführt noch einmal auf einer anderen Ebene. Datensätze werden jetzt viel, viel größer und chaotischer, Designs komplexer und statistische Verfahren anspruchsvoller. Mehrere Analysen werden kombiniert oder speziellere Modelle eingesetzt. Trotzdem bleibt eines konstant: Auch auf diesem Niveau überzeugt saubere Methodik meist mehr als unnötige Komplexität. Komplizierte Statistik rettet leider keine unklare Forschungsfrage, wie ich fast regelmäßig mit meinen Klienten aus dem Fachbereich Medizin ausfechten muss.
Wenn ich alle genannten Ebenen auf einen Satz reduzieren müsste, wäre es ungefähr dieser: Mit jeder Stufe des Studiums steigt weniger die Erwartung an spektakuläre Statistik und stärker die Erwartung, methodische Entscheidungen nachvollziehen, begründen und kritisch hinterfragen zu können. Genau dort unterscheidet sich eine Hausarbeit von einer Dissertation oft stärker als bei der Statistik selbst.
6. Skalenniveaus verstehen
Skalenniveaus beantworten eigentlich nur eine einfache Frage: Wie wurden Daten gemessen? Und genau davon hängt später ab, welche statistischen Verfahren überhaupt sinnvoll sind.
Bei einer Nominalskala werden Werte lediglich verschiedenen Kategorien zugeordnet. Geschlecht, Studiengang oder Wohnort wären typische Beispiele. Die Reihenfolge spielt keine Rolle. BWL ist nicht „mehr“ als Psychologie und Berlin nicht „größer“ als Köln. Hier werden häufig Häufigkeiten oder Chi-Quadrat-Tests genutzt.
Die Ordinalskala besitzt zusätzlich eine Reihenfolge. Zufriedenheit auf einer Skala von 1 bis 5 wäre ein klassisches Beispiel. Eine Person mit einer 5 ist zufriedener als jemand mit einer 2. Wie groß dieser Unterschied wirklich ist, bleibt allerdings offen.
Die Intervallskala besitzt gleiche Abstände zwischen Werten. Temperatur in Celsius wird häufig genannt. Der Unterschied zwischen 10 °C und 20 °C entspricht dem Unterschied zwischen 20 °C und 30 °C. Ein echter Nullpunkt fehlt jedoch.
Die Verhältnisskala enthält zusätzlich einen natürlichen Nullpunkt. Alter, Einkommen, Gewicht oder Schlafdauer gehören dazu. 0 Stunden Schlaf bedeutet tatsächlich kein Schlaf. Genau deshalb lassen sich hier deutlich mehr Berechnungen durchführen.
Rom wurde volkstümlich nicht an einem Tag erbaut.
Ich und mein Team können jedoch gar eine Mustervorlage für eine gesamte Bachelorarbeit in kürzester Zeit qualitativ hochwertig erstellen.
7. Deskriptive Statistik: Ein Abriss
Wenn SPSS oder R zum ersten Mal Ergebnisse ausgeben, erscheinen häufig Werte wie diese:
M = 3,84; SD = 0,92; Min = 1; Max = 5
Wenn Ihr das statistische Denken nicht gewohnt seid, schaut Ihr oft ungefähr so wie auf einen IKEA-Aufbauplan ohne Bilder. Hier müsst Ihr verstehen, dass diese Zahlen zunächst nur beschreiben, wie die Daten aussehen. Mehr nicht. Nehmen wir als Beispiel eine Befragung zur Prüfungsangst. Bevor untersucht wird, ob Neurotizismus, Stress oder Schlaf damit zusammenhängen, wird häufig zuerst beschrieben:
Wie hoch war die durchschnittliche Prüfungsangst?
Wie stark unterscheiden sich Antworten?
Wie alt waren Teilnehmende?
Gab es extreme Werte?
Ein Ergebnisteil könnte dann lauten:
Die Prüfungsangst der Stichprobe lag im Mittel bei 3,8 Punkten (SD = 0,9). Das Alter variierte zwischen 19 und 34 Jahren.
8. Daten visualisieren
Irgendwann kommt fast jede empirische Arbeit an den Punkt, an dem Zahlen nicht mehr nur beschrieben, sondern dargestellt werden sollen. Genau dann tauchen Diagramme auf. Die Darstellung von Daten hat einen simplen Zweck: Ergebnisse schneller verständlich machen.
Balkendiagramme eignen sich häufig für Gruppenvergleiche. Beispielsweise unterschiedliche Stresswerte zwischen Studiengängen.
Kreisdiagramme zeigen Anteile, etwa Geschlechterverteilungen. Werden oft genutzt. Nicht immer sinnvoll.
Histogramme helfen dabei zu erkennen, wie Werte verteilt sind. Gerade bei Normalverteilungen relevant.
Boxplots zeigen Streuungen, Medianwerte und mögliche Ausreißer. Viele ignorieren sie, obwohl sie oft schneller Probleme sichtbar machen als Tabellen.
Tabellen bleiben dennoch Standard in Ergebnisteilen, weil sie präziser sind als Grafiken.
Mein Tipp ist, dass Ihr Euch folgendes merkt: Eine gute Darstellung beantwortet im Idealfall sofort eine Frage. Schlechte Darstellungen erzeugen neue. Eure Betreuer erkennen an Diagrammen ziemlich schnell, ob Ihr Eure eigenen Daten verstanden habt oder nicht.
9. Hypothesen testen: Der Punkt, an dem viele anfangen, Statistik unnötig kompliziert zu finden
Spätestens hier tauchen Begriffe auf, die bei den meisten von uns ungefähr dieselbe Reaktion auslösen: Nullhypothese, Signifikanzniveau, p-Wert. Klingt zunächst kompliziert, verfolgt am Ende aber eine relativ einfache Idee. Fast jede empirische Arbeit versucht irgendwann eine Annahme zu prüfen. Angenommen die Forschungsfrage lautet: „Besteht ein Zusammenhang zwischen Stress und Prüfungsangst bei Studierenden?“
Dann entstehen im Hintergrund häufig zwei gegensätzliche Annahmen. Die Nullhypothese (H₀) behauptet zunächst, dass kein Zusammenhang existiert. Die Alternativhypothese (H₁) geht davon aus, dass ein Zusammenhang besteht. Statistik versucht anschließend nicht zu beweisen, dass die Alternativhypothese wahr ist. Stattdessen wird geprüft, wie plausibel die Nullhypothese anhand der Daten noch wirkt.
Genau hier erscheint später normalerweise der p-Wert. Wenn tatsächlich kein Zusammenhang bestehen würde, wären die beobachteten Daten eher unwahrscheinlich. Das heißt aber nicht, dass etwas bewiesen wurde und auch nicht automatisch, dass ein Ergebnis praktisch relevant ist. Ein kleines Beispiel macht das hoffentlich greifbarer. Stellen wir uns vor, untersucht werden Unterschiede in der Prüfungsangst zwischen Studierenden mit Nebenjob und ohne Nebenjob. Nach der Analyse ergibt sich: p = 0,018. Da dieser Wert kleiner als 0,05 ist, würde die Nullhypothese häufig verworfen werden. Die Daten sprechen eher dafür, dass Unterschiede bestehen könnten. Ein Ergebnissatz könnte dann lauten:
„Studierende mit Nebenjob zeigten signifikant höhere Prüfungsangst als Studierende ohne Nebenjob (p = .018).“
Das klingt zunächst eindeutig. Es fehlt jedoch eine weitere Frage:
Wie groß ist dieser Unterschied überhaupt?
Wenn sich die Mittelwerte nur minimal unterscheiden, kann ein Ergebnis statistisch signifikant sein, praktisch aber kaum Bedeutung besitzen. Genau deshalb werden häufig zusätzlich Effektgrößen betrachtet.
Ein stark anonymisierter Fall aus meinem Alltag sei hierfür exemplarisch herangezogen. Die Forschungsfrage lautete sinngemäß: „Beeinflusst die tägliche Social-Media-Nutzung depressive Symptome bei Studierenden?“
Kurz zum Setting: Eigene Datenerhebung, etwa 160 Teilnehmende, mehrere Skalen. Die Fragestellung war per se klar. Die Auswertung ignorierte das aber leider. Enthalten waren unter anderem mehrere t-Tests zwischen Altersgruppen, eine ANOVA nach Studienfach, zusätzliche Signifikanztests zwischen Schlafdauer und Geschlecht sowie Korrelationen zu Variablen, die in der eigentlichen Forschungsfrage nie vorkamen. Zusätzlich wurde ein p-Wert von 0,047 im Ergebnisteil so behandelt, als wäre damit die komplette Forschungsfrage beantwortet.
Doch was fast komplett ignoriert wurde, war, welche Hypothese überhaupt beantwortet werden sollte? Die Forschungsfrage zielte ja klar auf einen möglichen Zusammenhang zwischen Social-Media-Nutzung und depressiven Symptomen ab. Sinnvoll wäre also ungefähr folgende Reihenfolge gewesen:
Zunächst Daten beschreiben, anschließend Reliabilität der Skalen prüfen, danach Zusammenhänge untersuchen und gegebenenfalls über eine Regression genauer betrachten, wie stark Social-Media-Nutzung depressive Symptome vorhersagen kann.
Ich helfe unverändert auch bei der Erstellung von Hypothesen & Fragebögen.
Einfach kurz Hallo sagen:
10. Korrelationen verstehen
Korrelationen tauchen in empirischen Arbeiten häufig auf, weil viele Forschungsfragen am Anfang erstaunlich unspektakulär sind. Es geht oft nicht darum, etwas zu beweisen, sondern zunächst nur herauszufinden, ob zwei Dinge überhaupt gemeinsam auftreten. Besteht ein Zusammenhang zwischen Stress und Schlafqualität? Hängt Neurotizismus mit Prüfungsangst zusammen? Geht hohe Arbeitsbelastung mit geringerer Zufriedenheit einher? Solche Fragen landen relativ schnell bei Korrelationen. Die Berechnung selbst ist heute selten die Schwierigkeit. SPSS erledigt das in Sekunden. Anspruchsvoller wird meist die Interpretation danach.
Ein Korrelationswert bewegt sich typischerweise zwischen -1 und +1. Positive Werte sprechen eher dafür, dass zwei Variablen gemeinsam steigen. Negative Werte deuten eher darauf hin, dass mit zunehmender Ausprägung der einen Variable die andere sinkt. Werte nahe 0 zeigen häufig keinen erkennbaren linearen Zusammenhang. Ein Ergebnis von r = 0,62 wirkt zunächst stärker als r = 0,18, sagt aber noch nichts darüber aus, warum dieser Zusammenhang existiert. Genau an dieser Stelle entsteht in Ergebnisteilen regelmäßig ein Bruch zwischen Daten und Interpretation. Aus „Stress und Schlaf hängen zusammen“ wird plötzlich „Stress verschlechtert Schlaf“. Aus „Arbeitszufriedenheit korreliert mit Burnout“ entsteht „Unzufriedenheit verursacht Burnout“. Die Formulierungen wirken klein, verändern die Aussage jedoch vollständig.
Wenn eine Untersuchung beispielsweise zeigt, dass höhere Lernzeiten mit besseren Noten einhergehen, klingt die schnelle Schlussfolgerung nachvollziehbar: Mehr Lernen verbessert Leistungen. Vielleicht stimmt das sogar. Vielleicht lernen leistungsstarke Personen aber grundsätzlich strukturierter. Vielleicht schlafen sie besser oder besitzen andere Voraussetzungen. Vielleicht existieren mehrere Einflüsse gleichzeitig. Eine Korrelation trennt diese Dinge nicht sauber voneinander. Sie zeigt zunächst nur Muster. Und Muster sind noch keine Ursachen.
11. Gruppen vergleichen (t-Test und ANOVA)
Bis hierhin ging es häufig um Zusammenhänge. Also Fragen wie: „Steigt Variable A gemeinsam mit Variable B?“ Irgendwann ändern sich Forschungsfragen jedoch leicht und plötzlich lautet die Überlegung nicht mehr, ob etwas zusammenhängt, sondern ob sich Gruppen unterscheiden.
Die Formulierungen klingen dann ungefähr so:
Unterscheiden sich Männer und Frauen hinsichtlich ihrer Prüfungsangst?
Unterscheiden sich Personen im Homeoffice von Personen im Büro hinsichtlich ihrer Arbeitszufriedenheit?
Gibt es Unterschiede zwischen Studierenden verschiedener Studiengänge?
Nehmen wir eine Untersuchung zur Prüfungsangst. Angenommen, eine Gruppe von Studierenden arbeitet neben dem Studium mehr als 20 Stunden pro Woche und eine zweite Gruppe arbeitet gar nicht. Nun soll geprüft werden, ob sich beide Gruppen hinsichtlich ihrer Prüfungsangst unterscheiden. Die Daten könnten später ungefähr zeigen:
Gruppe ohne Nebenjob: Mittelwert = 2,8
Gruppe mit Nebenjob: Mittelwert = 3,7
Die Mittelwerte unterscheiden sich sichtbar. Reicht das bereits aus, um von einem echten Unterschied zu sprechen? Die Antwort ist not really. Denn Unterschiede entstehen manchmal auch zufällig. Genau deshalb taucht hier häufig der t-Test auf. Er prüft vereinfacht, ob sich zwei Gruppen statistisch voneinander unterscheiden oder ob beobachtete Unterschiede eher zufällig wirken könnten. Ein Ergebnis könnte beispielsweise ergeben: p = 0,012. Dann würde häufig angenommen, dass sich die Gruppen unterscheiden. Viele Studierende stoppen an dieser Stelle. In der Praxis folgt jedoch noch eine zweite Frage: Wie groß ist dieser Unterschied überhaupt?
Noch interessanter wird es, wenn nicht zwei Gruppen verglichen werden, sondern mehrere. Angenommen untersucht wird: Unterscheiden sich Studierende aus Psychologie, BWL und Medizin hinsichtlich ihres Stressempfindens? Jetzt existieren nicht mehr zwei Gruppen, sondern drei. An dieser Stelle erscheint häufig die ANOVA (Varianzanalyse).
Die ANOVA prüft zunächst nur: Gibt es irgendwo zwischen den Gruppen Unterschiede? Sie beantwortet nicht automatisch: Zwischen welchen Gruppen genau? Wenn eine ANOVA signifikant ausfällt, folgen häufig zusätzliche Tests, um die Unterschiede genauer einzugrenzen. Gerade hier entstehen viele Fehler, weil zumeist aus fehlendem Verständnis Verfahren gewählt werden, die zur Forschungsfrage gar nicht passen. Es gilt:
Wenn zwei Gruppen verglichen werden sollen, ist eine ANOVA häufig unnötig kompliziert.
Wenn mehrere Gruppen betrachtet werden, reicht ein einfacher t-Test meist nicht mehr.
Und wenn eigentlich Zusammenhänge untersucht werden sollen, wären beide Verfahren unpassend.
Hier geht es zum letzten Teil der statistischen Know-how-Reihe
Direkter Kontakt
📞 +49 176 57 95 85 04 (Whatsapp, Telegram)
© 2026. All rights reserved.
Rechtliches
Die Abschlusshelfer
Aroser Allee 159
13407 Berlin, DE